Hello, I have several farmers. Most work well, but some don’t and the reasons don’t appear obvious, for examples, one farmer has way more CPU or way more memory or way more bandwidth or way more plots etc.
The system that is not signing rewards once it’s plotting has 16x 8 TB nvme SSD, 2x 64 core Epyc Milan CPUs and 1 TB of DDR4-3200.
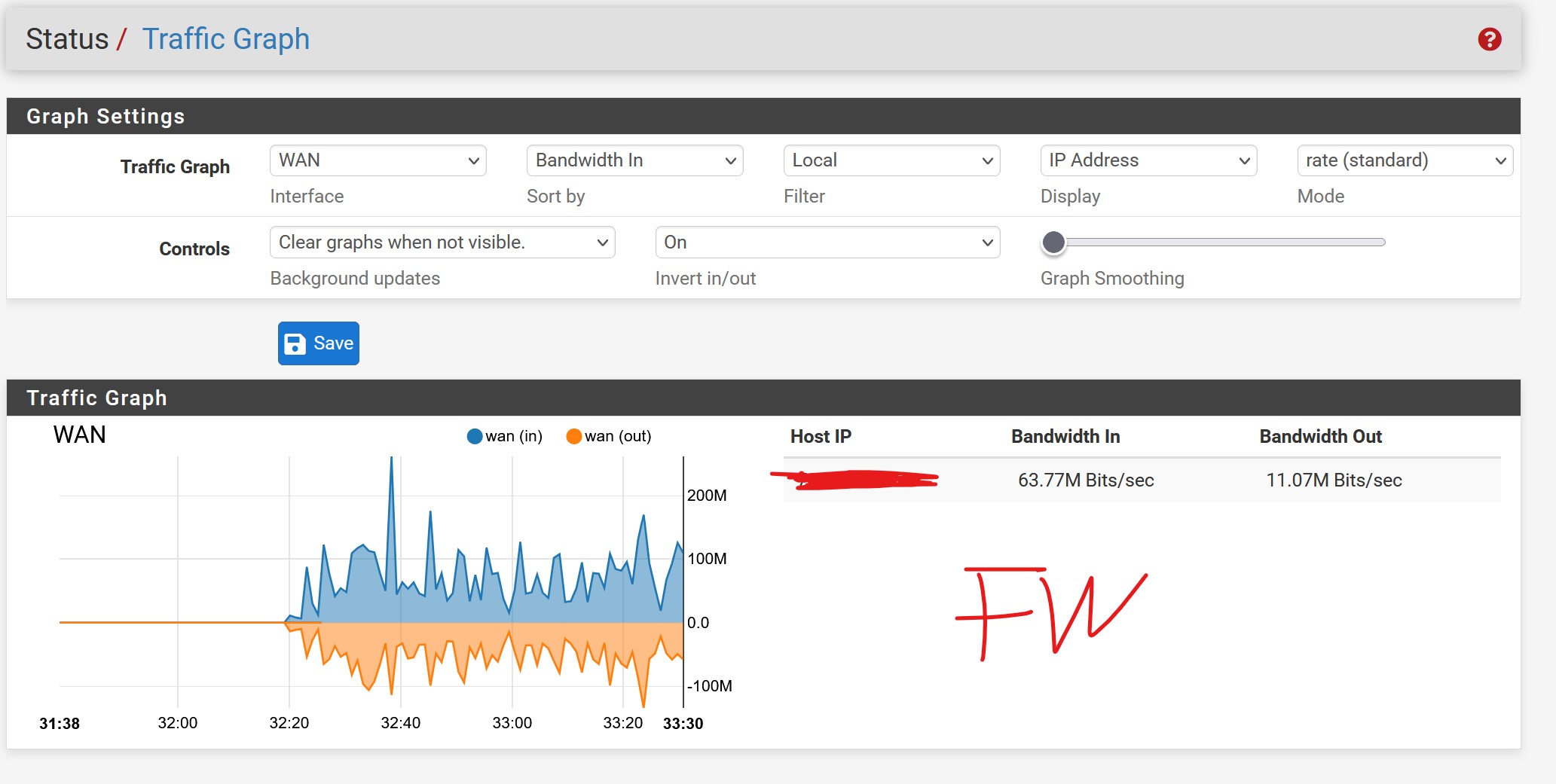
It’s signing rewards right after the restart of the farmers, but once it’s starting to plot no more rewards. I have build sept-11 myself and use the binary also on machines where it’s working as expected. This is running Centos9. I have 1 gbps fiber internet. The overarching internet load see screenshot from firewall (FW) doesn’t seem to be the bottleneck for anything.
On the multitail output you see three different farmer’s stdout because on the same machine I have 1 node and 3 farmers (under different ports) running. Each farmer has 5-6plots of 7,500 GB size.
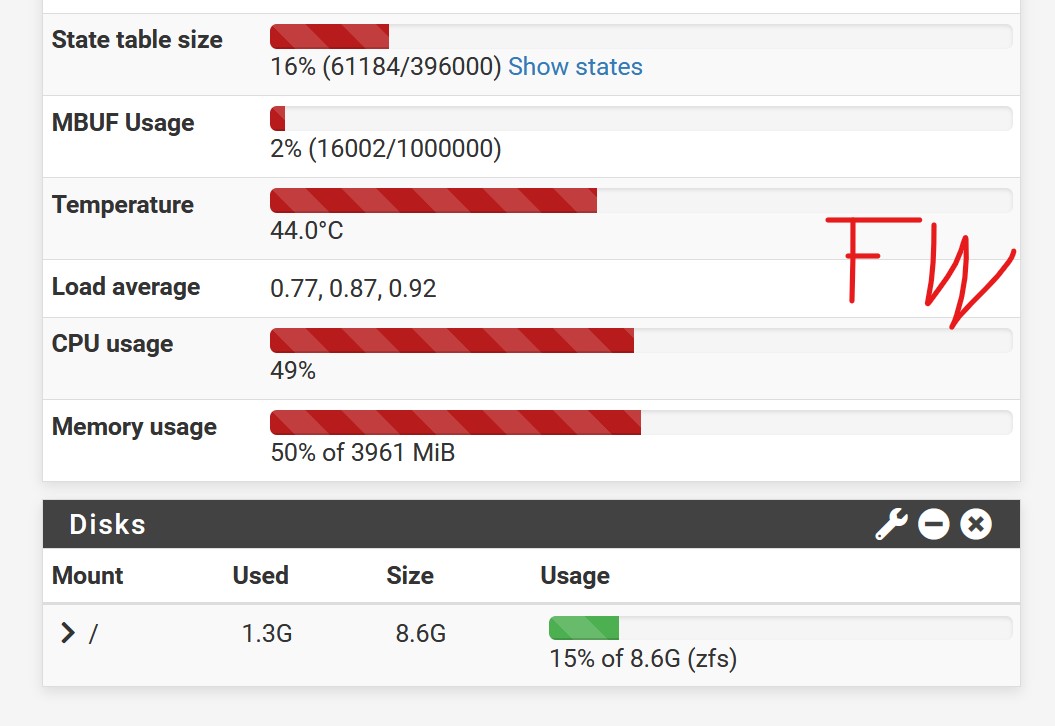
You also see the “little” memory this actually uses… Plus you see that across 16x NVME the sum is only like 400mb/s read… IO isn’t the obvious bottleneck…
I changed the value const PARALLELISM_LEVEL: usize = 4; to the value 4 from 20, now i don’t see any plotting anymore but only voting. Going to set it to 256 and try again.
You should use latest release that has fixes for farming during plotting and you should configure one farm per physical disk as documentation and numerous forum and Discord threads suggest. Looks like you’re not following those recommendations right now.
Thanks for your reply. There is only one farm per disk on dnode-4d. The machine has 16x drives, and in the search of reasons on why it’s not working I have split the 16x drives across three farmers, where each farmer still has 5-6 farms with dedicated drives.
On this specific system one single farming process cannot nearly exhaust the system’s resources, while three concurrent farmer processes get much closer to that. by observation three farmer processes plot each on 5-6 drives faster than a single process with 16 drives.
But that is not the issue, on this particular system no matter which configuration one or three farmers, as soon as plotting starts no more voting/rewards.
Right now trying to see if 13-2 will make a difference.
Single farmer should actually be better because it will have bigger cache of unique pieces, hence plotting will accelerate once cache is populated. For separate farmers you will have disjoined caches, which will potentially make things a bit smaller.
You can run things however you want, but it makes little sense the way I see it from implementation point of view.
I really like to stick to the original issue. One farmer or three, once the farmer starts plotting it’s not voting/signing anymore. I changed from one farmer to three as a test to see if that makes a difference. But it doesn’t. While doing so observed a couple more things.
I can change easily back to one farmer, with 16x drives and it’s still not voting/signing, once it’s plotting.
What can I do to find out why it’s not voting/signing while plotting?
I guess you’ll have to wait for plotting to finish. That many plots is quite heavy for CPU and it will impact farming. The next iteration of the protocol (likely Gemini 3g) will have a prediction window that will make it less likely.
So I changed that system to have 2 farmer processes, each 8x 8TB drives, 8 farms for each. The split needed bc of the 70 TiB limit
For each farmer, I know from previous log file they had plotted about 14% of the 7500 GB plot size. For each farmer I changed 7 of 8 plots down to 1 TB that should make them fully plotted.
For each farmer I left one plot at the original 7500 GB size.
What I see what happened over night, each 7500 GB plot continues to plot, but all 2x farmers x 1 TB plots are re-plotting and no voting/signing.
So there seems something going on with plotting, re-plotting and blocking the voting/signing?
If you see a lot of replotting, it means sectors were plotted a while ago and likely not eligible for rewards anymore until they are replotted. Also check CPU usage, if machine is overwhelmed there will not be enough CPU power left for farming until plotting/replotting is over.
88.4% CPU load can be overloaded. There are other bottlenecks like memory bandwidth as well. So I’d just wait for CPU usage to calm down at least. Plotting is designed to use reasonable amount of RAM and writes things to disk sequentially, but otherwise is CPU-bound (unless piece retrieval is slow, then it’ll be network-bound).
I am not worried at all about 84% CPU load. But there are some parts that play a role with this dual epyc system, maybe it would benefit from running on one numa only. I will try that our over night.
Blockquote
numactl --cpunodebind=0 --membind=0 farmer-bin1…
numactl --cpunodebind=1 --membind=1 farmer-bin2…
That will limit the amount of data going between numa nodes (sockets)
I think that’s the challenge with the “chiplet” CPUs. Running one farmer per socket has improved the situation to now each process is plotting, re-plotting and signing. If this is really memory bandwidth bound problem, should actually try setting NPS4. I may try, but not now, I keep watching it.